1. Introduction
Hello! We are a writer team from Definer Inc.
CRUD (Create, Read, Update, Delete) processing refers to the basic operations performed on data in a database. DynamoDB is a fully managed NoSQL database service provided by AWS. It offers a flexible and scalable platform for storing and retrieving data. CRUD processing of DynamoDB data involves performing these fundamental operations to manage data stored in DynamoDB tables.
In this issue, you are wondering about the use of the CRUD process to DynamoDB.
Let's take a look at the actual screens and resources to explain in detail.
2. Purpose/Use Cases
The purpose of CRUD processing in DynamoDB is to provide a comprehensive set of operations for managing data in a flexible and efficient manner.
By combining these CRUD operations, developers can effectively manage the lifecycle of data in DynamoDB. They can create new records, retrieve existing data, update attributes as needed, and delete data that is no longer required. This provides the ability to maintain data consistency, handle user interactions, and support various application scenarios.
Suppose you are building a real-time chat application that requires low-latency and seamless scaling to handle millions of concurrent users. In this scenario, DynamoDB is a better choice over RDS as DynamoDB is good at: Low-latency and Scalability, Schema-less and Flexible Data Model, No Joins and Complex Queries, Fully Managed Service.
This article is written for the purpose of understanding CRUD processing in Amazon DynamoDB.
It is a collection of information and practices that can be used as a reference when you want to develop with DynamoDB, a NoSQL, in the IT field.
3. What is DynamoDB?
DynamoDB is a fully managed NoSQL database service provided by AWS.
DynamoDB is a simple key-value type and can achieve fast performance.
As long as the primary key, consisting of a hash key and a sort key, is unique, the table items can be freely configured.
Here, we will also review NoSQL in comparison with RDBMS.
・Data can be stored in a variety of formats, including key-value type and document type, in addition to the matrix table format of RDBMS.
・Compared to RDBMS, data accuracy (ACID characteristics: [inseparability, consistency, independence, and persistence]) is inferior, but the advantages are high performance and easy scaling.
・Data manipulation is often performed via object-based APIs, whereas RDBMSs are performed via SQL.
4. Setup of Lambda and DynamoDB
We will immediately execute the CRUD process against DynamoDB.
① Creating a Lambda for testing:
To create a Lambda function for testing, follow these steps:
- Access the AWS Lambda console.
- Click on the "Create Function" button to start creating a new Lambda function.
- Choose a name for your function and select "Python 3.9" as the runtime.
- You will need to attach an IAM role to the Lambda function that has appropriate permissions to access DynamoDB. You can create a new role or choose an existing one that has the necessary permissions to interact with DynamoDB.
- Configure other settings such as the execution timeout, memory allocation, and VPC (if needed) according to your requirements.
- Write the code for your Lambda function, including the necessary logic for interacting with DynamoDB (e.g., CRUD operations).
- Once you have completed the function configuration and code, click the "Create Function" button to create your Lambda function.
With the Lambda function created, you can now test and invoke it, and it will be able to interact with DynamoDB using the assigned IAM role.
② Creating DynamoDB:
To create a DynamoDB table and populate it with sample data, follow these steps:
- Access the AWS DynamoDB console.
- Click on the "Create Table" button to start creating a new DynamoDB table.
- Specify a name for your table, such as "employee".
- Define the primary key for your table. In this example, set the partition key as "id" (assuming it represents the unique identifier for each employee record).
- Configure other table settings, such as provisioned capacity or on-demand capacity mode, depending on your requirements.
- Click the "Create" button to create the DynamoDB table.
The following table has been created.
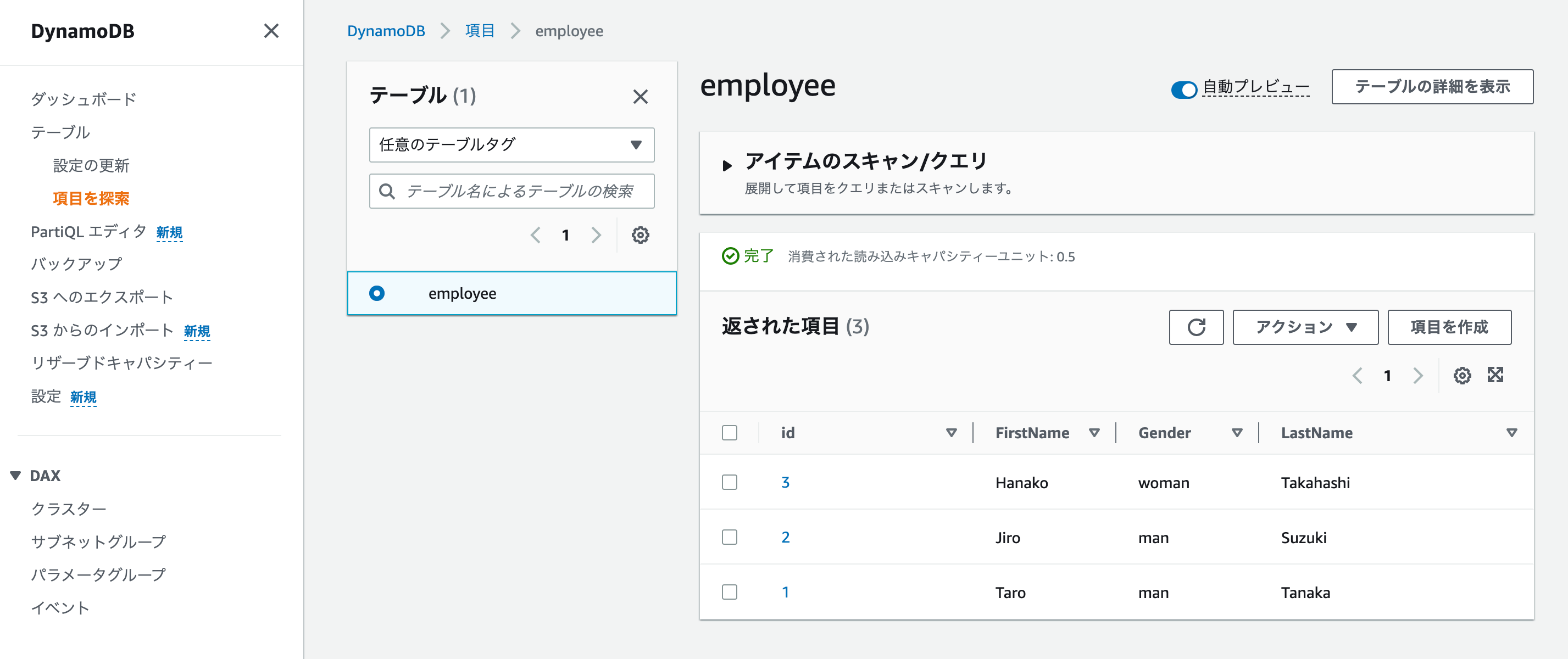
5. Read process for DynamoDB tables
We will immediately execute the CRUD process.
We will start with the Read process.
Copy and paste the following into the Lambda and execute.
Get specific data with "get_item".
import json
import boto3
from boto3.dynamodb.conditions import Key,Attr
def lambda_handler(event,context):
__TableName__ = "employee"
Primary_Column_Name = 'id'
Primary_Key="1"
columns=["LastName","FirstName","Gender"]
client = boto3.client('dynamodb')
DB=boto3.resource('dynamodb')
table=DB.Table(__TableName__)
## Read
response=table.get_item(
Key={
Primary_Column_Name:Primary_Key
}
)
print(response["Item"]) Read was successful with the following results.
{'Gender': 'man', 'id': '1', 'FirstName': 'Taro', 'LastName': 'Tanaka'} 6. CRUD processing for DynamoDB tables
Next, let's execute the Create, Update, and Delete processes.
Deploy the following code to Lambda and execute it.
It describes the process of adding data with id=4 and deleting data with id=2.
put_item" is Create/Update data and "delete_item" is delete data.
import json
import boto3
from boto3.dynamodb.conditions import Key,Attr
def lambda_handler(event,context):
__TableName__ = "employee"
Primary_Column_Name = 'id'
columns=["LastName","FirstName","Gender"]
client = boto3.client('dynamodb')
DB=boto3.resource('dynamodb')
table=DB.Table(__TableName__)
## Create / Update
Primary_Key="4"
response=table.put_item(
Item={Primary_Column_Name:Primary_Key,
columns[0]:"Saburo",
columns[1]:"Ito",
columns[2]:"man"
})
## Delete
Primary_Key="2"
response=table.delete_item(
Key={
Primary_Column_Name:Primary_Key
})
## Print All Data
response=table.scan(
FilterExpression = Attr('id').gte("0")
)
for item in response["Items"]:
print(item) The following results are displayed, confirming that the CRUD process is working!
{'Gender': 'man', 'id': '1', 'FirstName': 'Taro', 'LastName': 'Tanaka'}
{'Gender': 'man', 'id': '5', 'FirstName': 'Itoa', 'LastName': 'Saburo'}
{'Gender': 'man', 'id': '4', 'FirstName': 'Ito', 'LastName': 'Saburo'}
{'Gender': 'woman', 'id': '3', 'FirstName': 'Hanako', 'LastName': 'Takahashi'} 7. Cited/Referenced Articles
Notes on CRUD processing in DynamoDB! | Liucom Tech Blog
【Introduction】DynamoDB that made me suffer | Future Technology Blog
Notes on using DynamoDB Local - Amazon DynamoDB
DynamoDB Streams Change Data Capture - Amazon DynamoDB
Notes on CRUD processing in DynamoDB! | Liucom Tech Blog
Management of DynamoDB provisioned capacity table settings ...
Error handling in DynamoDB - Amazon DynamoDB
8. About the proprietary solution "PrismScaler"
・PrismScaler is a web service that enables the construction of multi-cloud infrastructures such as AWS, Azure, and GCP in just three steps, without requiring development and operation.
・PrismScaler is a web service that enables multi-cloud infrastructure construction such as AWS, Azure, GCP, etc. in just 3 steps without development and operation.
・The solution is designed for a wide range of usage scenarios such as cloud infrastructure construction/cloud migration, cloud maintenance and operation, and cost optimization, and can easily realize more than several hundred high-quality general-purpose cloud infrastructures by appropriately combining IaaS and PaaS.

9. Contact us
This article provides useful introductory information free of charge. For consultation and inquiries, please contact "Definer Inc".
10. Regarding Definer
・Definer Inc. provides one-stop solutions from upstream to downstream of IT.
・We are committed to providing integrated support for advanced IT technologies such as AI and cloud IT infrastructure, from consulting to requirement definition/design development/implementation, and maintenance and operation.
・We are committed to providing integrated support for advanced IT technologies such as AI and cloud IT infrastructure, from consulting to requirement definition, design development, implementation, maintenance, and operation.
・PrismScaler is a high-quality, rapid, "auto-configuration," "auto-monitoring," "problem detection," and "configuration visualization" for multi-cloud/IT infrastructure such as AWS, Azure, and GCP.